AI Paper Review/Deep RL Papers [EN]
[3줄 RL] Back to basic
Bellman
2021. 8. 10. 23:56
<arxiv> https://arxiv.org/abs/1312.5602
Playing Atari with Deep Reinforcement Learning
We present the first deep learning model to successfully learn control policies directly from high-dimensional sensory input using reinforcement learning. The model is a convolutional neural network, trained with a variant of Q-learning, whose input is raw
arxiv.org
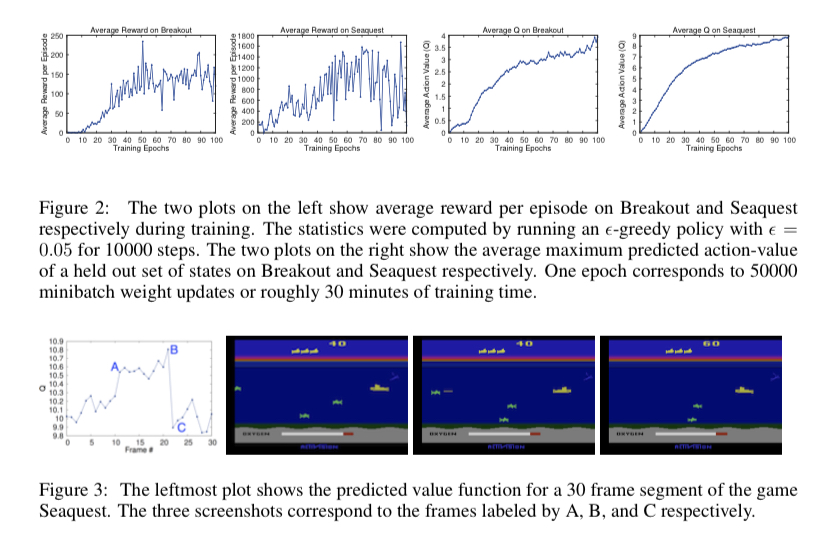
1. 기존 Tabular Q-Learning은 image와 같은 observation에 대응 불가하고 차원의 저주에 빠져 허우적댄다.
2. 그럼 Q함수를 CNN으로 근사하면 어떨까? 거기다 리플레이 메모리 같은것도 붙이면 더더욱 좋아지지 않을까?

3. 우리는 아타리 게임을 성공적으로 플레이할 수 있는 DQN(Deep Q Network)를 창시했다.