[3줄 RL] COBRA!
2021. 8. 15. 23:59ㆍAI Paper Review/Deep RL Papers [EN]
<arxiv> https://arxiv.org/pdf/1905.09275.pdf
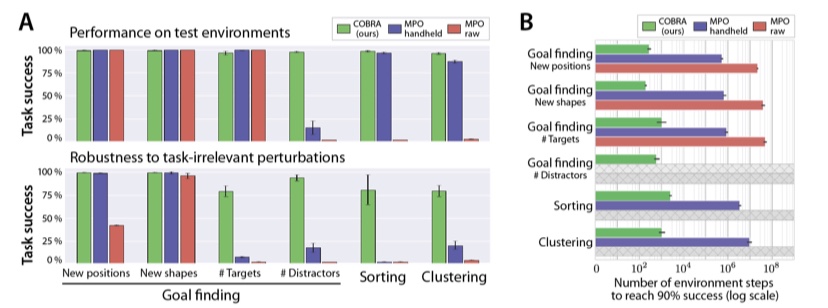
1. Goal-Objected RL 셋업은 매우 Sample-Efficient한 접근을 가능하게 했고, Model-Based+Representation Learning또한 Sample Efficiency를 업그레이드 했지만 아직 복잡한 환경에 사용하기는 어렵다. Curiosity 기반 Exploration은 매우 Sparse한 환경에서도 Robust한 학습을 보여줬다.
2. 이거 3가지를 다 섞은 모델은 어떨까? Object들의 Representation을 Curiosity에 기반해 잘 뽑아낼 수 있으면서도 Robust하고 Sample-Efficient하지 않을까? COBRA를 소개합니다!

3. Curiosity에 기반한 학습으로 Object들의 Representation을 잘 뽑을 수 있었고, 그에 따라 성능과 Robustness가 향상되었다.

'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] 놀랍도록 단순한 자가지도 오프라인 강화학습 (0) | 2021.08.20 |
|---|---|
| [3줄 RL] Curiosity+Contrastive=Sample Efficiency (0) | 2021.08.14 |
| [3줄 RL] Back to basic (0) | 2021.08.10 |
| [3줄 RL] 에이전트는 궁금해요 (0) | 2021.08.06 |
| [3줄 RL] RL + Contrastive = sample efficiency (0) | 2021.08.01 |