[3줄 RL] RL+Self-Supervised=Adaptation
2021. 7. 15. 01:13ㆍAI Paper Review/Deep RL Papers [EN]
<openreview> https://openreview.net/pdf?id=o_V-MjyyGV_
1. 강화학습에서 Generalization은 굉장히 큰 문제인데, 가령 Sim-to-real 문제처럼 태스크는 같지만 observation이 다른 텍스쳐로 들어오는 문제가 있다.
2. 그렇다면 이러한 문제를 해결하는 핵심은 새로 바뀐 observation에 잘 adaptation 되도록 뉴럴넷을 재학습시키는 것이다. Visual Representation을 배우는데 좋은 방법인 Self-Supervised Learning을 사용한다. SSL 태스크는 rotation prediction 등 다양하게 사용할 수 있다.
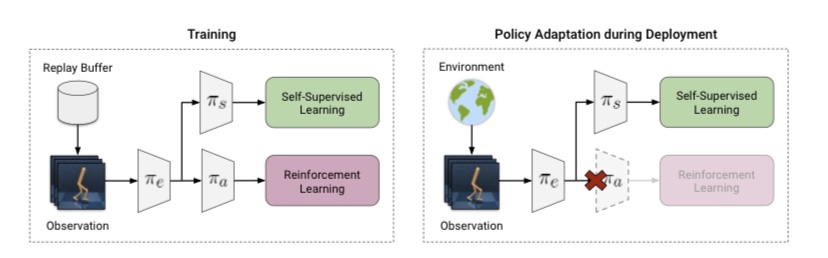
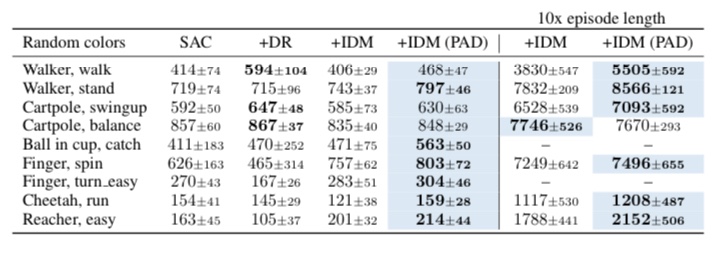
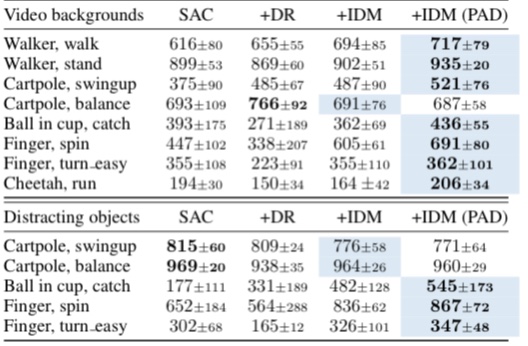
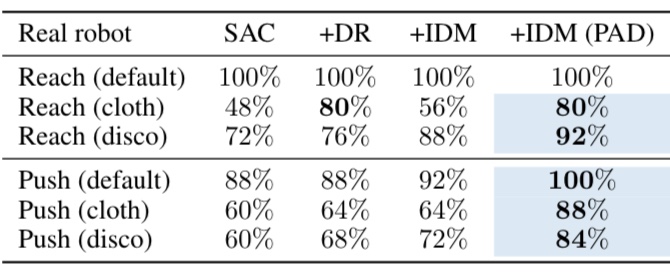
3. 로봇 매니퓰레이터 sim-to-real, 장애물 넣기나 백그라운드를 바꾼 Deepmind Control 태스크 등에서 Adaptation을 잘 하는 것을 볼 수 있다. stationary 여부와 상관없이 잘 되는 것을 볼 수 있다.

'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] 리워드 없이도 배운다 (1) | 2021.07.19 |
|---|---|
| [3줄 RL] 운송수단도 RL로 (0) | 2021.07.18 |
| [3줄 RL] 재무부 대신 에이전트 (0) | 2021.07.13 |
| [3줄 RL] SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environme (0) | 2021.07.02 |
| WHAT MATTERS FOR ON-POLICY DEEP ACTOR-CRITIC METHODS? A LARGE-SCALE STUDY (0) | 2021.06.16 |