[3줄 RL] 큐러닝의 고질병을 해결하다
2021. 7. 24. 20:07ㆍAI Paper Review/Deep RL Papers [EN]
<openreview> https://openreview.net/pdf?id=Bkg0u3Etwr
1. q-learning에서 underestimation 또는 overestimation bias는 q-learning에서 argmax Q(s,a)를 타겟으로 사용해 발생하는 고질적인 문제이다. 어떤 환경에서는 underestimation이, 어떤 환경에서는 overestimation이 나쁘다.

2. 이런 것을 보완하기 위해 double q-learning이 고안되기도 했지만 이것은 과도한 underestimation을 가져오기 때문에, 본 논문에서는 Q함수를 N개 사용하고 그중 가장 작은 것을 타겟으로 사용하는 maxmin q-learning을 제안한다.
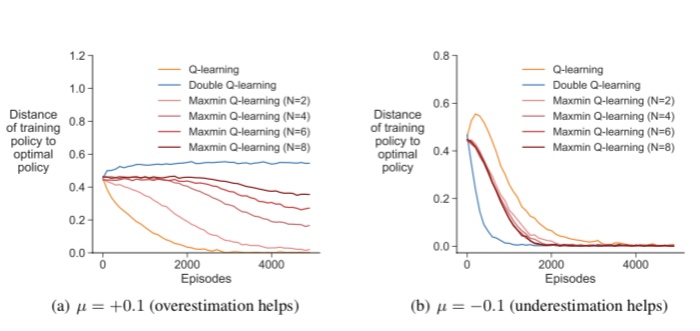

3. 이것을 DQN에 적용하게 되면 여러개의 타겟 큐함수를 만들어놓고 매스텝 랜덤하게 그중 하나만 업데이트에 사용하는 방식을 취하면 된다. 이 방법을 통해 overestimation을 줄여 에이전트의 최종 성능이 기존 방법론들에 비해 유의미하게 향상된 것을 볼 수 있다.


'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] RL로 QP 풀기 (0) | 2021.07.30 |
|---|---|
| [3줄 RL] 빨간 Q (0) | 2021.07.28 |
| [3줄 RL] 과학적 발견도 에이전트에게 맡겨둬! (0) | 2021.07.21 |
| [3줄 RL] 리워드 없이도 배운다 (1) | 2021.07.19 |
| [3줄 RL] 운송수단도 RL로 (0) | 2021.07.18 |