[3줄 RL] RL로 QP 풀기
2021. 7. 30. 01:30ㆍAI Paper Review/Deep RL Papers [EN]
<arxiv> https://arxiv.org/pdf/2107.10847.pdf
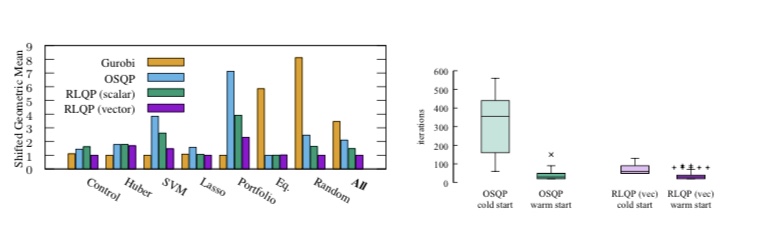
1. OSQP의 first-order optimization은 임베디드 제어 등에서 큰 역할을 한다. 또한 최근 강화학습을 이용해 combinatorial optimization 문제를 해결하는 등의 사례가 늘고 있다.
2. 이에 따라 QP 솔버의 하이퍼파라미터를 기존 휴리스틱한 방법이나 사람이 직접 튜닝하는 대신 RL(TD3)을 사용해 튜닝하는 프레임워크를 본 논문에서는 제안하고 있다.

3. 실제로 성능이 큰 폭으로 개선된 것을 볼 수 있다. 전통적인 제어등 최적화 분야에서 강화학습이 제어기 자체를 e2e로 대체하는 접근보다 하이퍼파라미터 튜닝 등 최적화 관점에서 접근하는게 더 빠르고 효율적이라는 생각을 항상 가지고 있다.
'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] 에이전트는 궁금해요 (0) | 2021.08.06 |
|---|---|
| [3줄 RL] RL + Contrastive = sample efficiency (0) | 2021.08.01 |
| [3줄 RL] 빨간 Q (0) | 2021.07.28 |
| [3줄 RL] 큐러닝의 고질병을 해결하다 (1) | 2021.07.24 |
| [3줄 RL] 과학적 발견도 에이전트에게 맡겨둬! (0) | 2021.07.21 |