2021. 6. 12. 23:53ㆍAI Paper Review/Deep RL Papers [EN]
<arxiv> https://arxiv.org/pdf/2106.01345.pdf
Instead of training a policy through conventional RL algorithms like temporal difference (TD) learning, We will train transformer models on collected experience using a sequence modeling objective.
0. 기존 RL의 학습방법과 Credit Assignement Problem
기존 RL은 위대한 수학자 Bellman에 의해 만들어진 Bellman Equation, 즉 TD를 이용해 학습했다. TD 러닝의 아이디어는 아주 간단하다. t스텝에는 t+1 스텝의 리워드를 알 수 없다. 그러므로 t~T까지의 discounted return을 apprioximate 한다. t+1 스텝에는 t+1 스텝의 리워드를 알 수 있고, t+1~T까지의 discounted return을 apprioximate 할 수 있다. 서로 뺀 값을 제곱하면 (t+1 시점의 실제 리워드 - t+1 시점의 예측 리워드) ^ 2가 된다. 이것을 최소화하도록 학습하면 discounted return의 apprioximator, 가령 Value Function이나 Q Function 따위가 정확해지게 되는 것이다.

이것을 계속 반복하다 보면, Credit Assignment가 일어나게 된다. 강화학습에서 Credit Assignment는 매우 중요한 문제다. Credit Assignment란, trajectory 중 어떤 step이 sum of discounted reward, 즉 return에 가장 많이 영향을 미쳤는지를 알아내는 문제다. TD 러닝을 이용해 계속 학습하다 보면 q function이 뒤로 propagation 되면서 점점 정확해지게 되고, 결국에는 Q*에 수렴하며 Credit Assignment를 완벽하게 할 수 있게 된다.

그렇지만 이것은 전체 trajectory를 보며 credit assignment를 하는게 아니라 그냥 한 transaction에 대해 step-by-step으로 업데이트 해 나가는 것이기 때문에, 이것이 많은 태스크에서 credit assignment를 힘들게 만든다. 특히 sparse한 리워드를 가진 환경이나, 환경에 별 영향을 미치지 못하는 액션들이 trajectory에 많이 쌓여 있어 노이즈를 준다면 (본 논문에서 지적된 "distractor signal") 더더욱 그렇다. 위에 생쥐는 여러 스텝을 진행하고 보상 한번을 받는다. 그렇다면 생쥐가 레버를 당긴 것이 보상을 받는데 더 큰 도움이 되었을까, 아니면 전구를 만난 게 더 큰 도움이 되었을까? 이것이 강화학습의 오랜 난제, Credit Assignment Problem이다.
이거 그 핫한 Decision Transformer 논문 리뷰해주는 글 아니었냐? 왜 CAP만 주구장창 다루고 있냐? 라고 하신다면, 그것은 오해다. 필자는 Decision Transformer가 왜 대단하고 멋진 알고리즘인지 느끼려면 CAP에 대한 이해와 고민, RL을 필드에 경험해본 사람이라면 고충이 있어야 된다고 생각한다. (필자는 최근에 CAP로 인해 푸는 태스크에게 고통받고 있다) 그래서 Credit Assignment Problem을 길게 설명한 것이니 이해해주시길.
1. Decision Transformer
1.1 Self Attention과 Credit Assignment
드디어 본론이다. Decision Transformer는 저자들에 의해 "TD 없는 Transformer 기반의 Sequantial Modeling 을 사용한 강화학습" 이라고 소개한다. TD로 학습하는 대신, 이미 만들어진 Trajectory에 대해 Sequential Modeling Objective를 사용해 Transformer 모델을 업데이트 하는 알고리즘인 것이다. Transformer 하면 무엇이 생각나는지 물었을 때, 대부분 어텐션이라고 답할 것이다. 어텐션은 말그래도 어떤 입력에 "집중" 하는 매커니즘이다. 이것을 Credit Assignment Problem과 엮어서 생각해보자. 직관적으로도 Self-Attention을 이용해 Credit Assignment Problem을 풀면, TD 러닝보다 훨씬 잘 풀릴 것 같다. 저자들은 실제로 Credit Assignment Problem을 "bypass" 한다는 표현을 썼다.
1.2 Offline Reinforcement Learning과 Decision Transformer
1.1에서도 눈치챘겠지만 Decision Transformer는 Offline RL 알고리즘이다. Offline RL은 환경과 Interaction 하지 않고 이미 존재하는 trajectory의 batch를 이용해 학습하는 방법이다. 이것이 imitation learning과 다른 점은 꼭 trajectory가 expert에 의해 만들어진 optimal policy가 아니어도 된다는 점이다. 이론적으로는 완전히 랜덤한 액션으로 만든 trajectory만 가지고도 학습을 하는 것이 Offline RL의 목적이다. 기존 offline RL은 error propagation과 value overestimation 등의 문제가 있었다. TD 러닝으로 인한 문제이다.
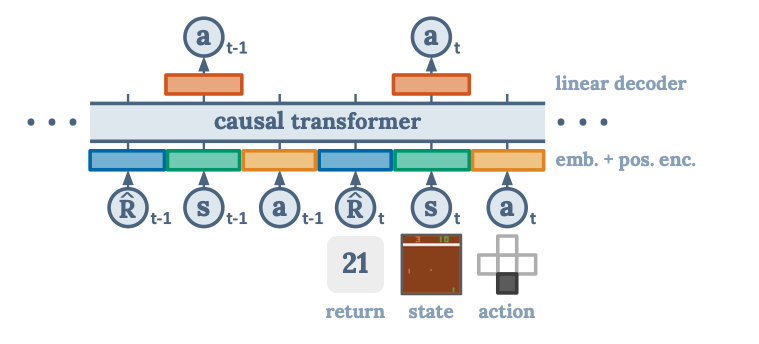
하지만 Decision Transformer 같은 Sequential Modeling 방법은 전혀 그런 문제가 없다. Decision Transformer는 state, action, return을 학습하는 autogressive generative model을 만든다 (아키텍쳐는 유명한 자연어 모델인 GPT 시리즈와 같다). 이것을 이용하여 기존 offline reinforcment learning의 policy sampling을 줄이는 것이다. 기존 방법과 같이 state로부터 optimal action을 이끌어 내는 모델이 아니라, optimal action을 쿼리하기 위해서 optimal return의 토큰을 넣으면 되는 것이다. 모델 구조를 시각화하면 다음과 같다.
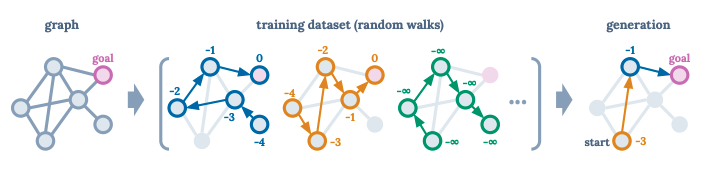
이러한 방법을 이용하여 graph에서 optimal trajectory를 찾는 문제를 랜덤한 trajectory만 가지고 "Dynamic Programming 없이" 해결했다. 1.2에 설명한 방법대로 starting state로 initial condition을 주고, 매 노드마다 highest return을 generating 하는 방법으로 이러한 문제를 풀 수 있다는 것이다.
1.3 Training
트레이닝은 정말 간단하다. R, s, a, t의 임베딩을 트랜스포머 모델에 넣고, a를 예측한다. 예측된 a와 실제 a의 L2 loss를 줄이는 방향으로 transformer를 학습시킨다. 이렇게 학습하고 나중에 R에 optimal return을 넣고 쿼리하면, 그 리턴을 받기 위한 a를 얻을 수 있다. evaluation step는 그냥 일반 강화학습과 같다. 수도코드는 뭔가 파이썬 스럽고 읽기 좋게 잘 써놨다. 역시 OpenAI!

2. Experimental Results
놀랍게도 이렇게 간단한 트랜스포머 학습법으로 Decision Transformer는 유명한 Offline RL 벤치마크인 CQL(Conservative Q-Learing)과 BC(Behavioral Cloning)를 이긴다. 참고로 CQL은 Model Free Offline RL SOTA이다.

특히 Key-to-door에서 압도적인 성적을 보이는데, 직관적으로 해석해보자면 distractor signal이나 sparse reward로 부터 생기는 어려운 Credit Assignment Problem을 잘 풀어나갈 수 있는 능력 때문인 것 같다.
2.1 Atari
RL 논문이라면 빠질수 없는 벤치마크다. 아타리를 학습하기 위해 사용한 데이터셋은 DQN-Replay 데이터셋으로, 학습 중 수집된 50M 샘플 중 500K 샘플만을 사용한다. 벤치마크는 TD Offline RL 알고리즘인 CQL과 REM, Off-policy RL 알고리즘인 QR-DQN, 마지막으로 BC를 사용하였다. 반 이상의 태스크에서 SOTA를 달성했고, 나머지 태스크 또한 매우 높은 성능을 보여준다.

2.2 OpenAI Gym
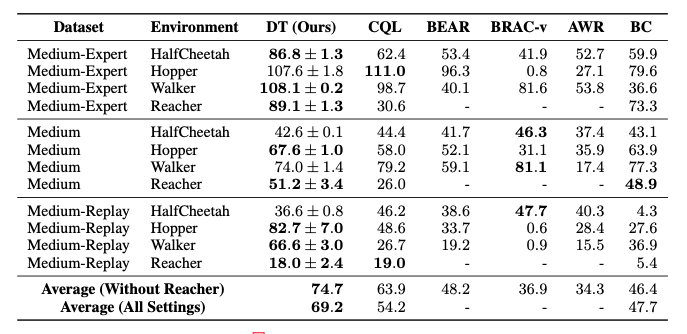
OpenAI Gym에 있는 D4RL 벤치마크 환경들을 상대로도 실험을 진행하였다. CQL, BEAR, BRAC, AWR 등의 Offline RL 알고리즘과 BC를 벤치마크로 하여, 반 이상의 태스크에서 SOTA를 달성했다. 사용된 데이터셋은 3가지이다.

3.Discussion
개인적으로 필자는 Decision Transformer에서 어쩌면 이것이 RL을 한 단계 진보시켜줄 것이라는 것을 느꼈다. RL의 오랜 과제인 Credit Assginment Problem을 Self-Attention을 이용해 해결하는 접근은 몇몇 있어왔지만, 유의미한 결과를 내지 못했다. 하지만 이 연구에서는 그것을 아주 멋지게 해결했다고 생각한다. Online RL 세팅에서도 Self-Attention을 이용하여 Credit Assignment Problem을 푸는 것이 유의미할 것 같고, 아마도 후속 연구를 진행 중일것으로 예상한다. 기대가 많이 되는 논문이다.
4. materials to understand this article
- Richard S Sutton and Andrew G Barto. Reinforcement learning: An introduction. MIT Press, 2018.
- Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Informa- tion Processing Systems, 2017.
- Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.
'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environme (0) | 2021.07.02 |
|---|---|
| WHAT MATTERS FOR ON-POLICY DEEP ACTOR-CRITIC METHODS? A LARGE-SCALE STUDY (0) | 2021.06.16 |
| Evolving Reinforcement Learning Algorithms (0) | 2021.06.01 |
| Munchausen Reinforcement Learning (0) | 2021.05.31 |
| Self-Imitation Advantage Learning (SAIL) (1) | 2021.05.31 |