2021. 5. 31. 00:56ㆍAI Paper Review/Deep RL Papers [EN]
<arxiv> https://arxiv.org/abs/2012.11989
Self-Imitation Advantage Learning
Self-imitation learning is a Reinforcement Learning (RL) method that encourages actions whose returns were higher than expected, which helps in hard exploration and sparse reward problems. It was shown to improve the performance of on-policy actor-critic m
arxiv.org
1. Self imitation reinforcement learning
Self-imitation learning is a Reinforcement Learning (RL) method that encourages actions whose returns were higher than expected
2. This method
This method defines "higher reward than expected" using advantage function A(s, a) = Q(s, a) - V(s)
The Proposed Method is encouraging(redefining) reward with the equation below
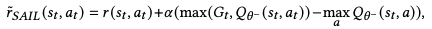
I can see intuitively that this encourages unexpected high returns.
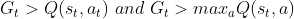
the equation above means that the returns were bigger than expected, and this encourages the reward. in another case, it penalizes the reward. so this method can define the unexpected high reward well.
So the corresponding loss function is,
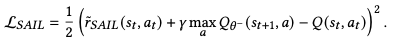
This method is about training q function(action-value function), which many off-policy RL algorithm does. So this method can be used as an off-policy RL method with a replay buffer.
Gathering all together leads us to the pseudocode below:

Experimental results:
1. SAIL outperforms both DQN(Deep Q Networks), IQN(Implicit Quantile Networks) in the atari57 benchmark

SAIL dramatically increased the performance in few Atari games
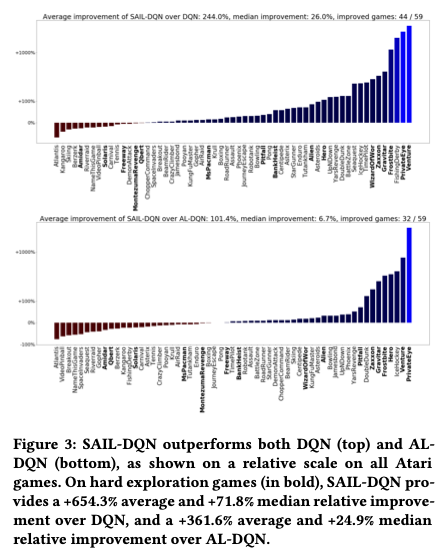
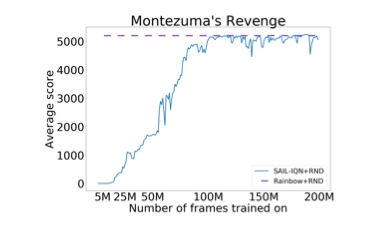
Plus, It shows that this is a robust method using the game "Montezuma's Revenge", which is known as a hard-exploration game. It has been a challenge for reinforcement learning algorithms to solve this game well.
Disclaimer:
This is a short review of the paper. it only shows a few essential equations and plots.
If needed, always read the full paper :)
Materials that you need to understand this post:
0. Reinforcement Learning: An introduction (Richard Sutton)
1. Playing Atari With Deep Reinforcement Learning (Minh et al)
2. Implicit Quantile Networks for Distributional Reinforcement Learning (Dabney et al)
3. Self-Imitation Learning (Oh et al)
'AI Paper Review > Deep RL Papers [EN]' 카테고리의 다른 글
| [3줄 RL] SMiRL: Surprise Minimizing Reinforcement Learning in Unstable Environme (0) | 2021.07.02 |
|---|---|
| WHAT MATTERS FOR ON-POLICY DEEP ACTOR-CRITIC METHODS? A LARGE-SCALE STUDY (0) | 2021.06.16 |
| Decision Transformer: Attention is all RL Need? (0) | 2021.06.12 |
| Evolving Reinforcement Learning Algorithms (0) | 2021.06.01 |
| Munchausen Reinforcement Learning (0) | 2021.05.31 |